Principales tareas y objetivos
-
La principal tarea del Departamento de Tecnologías de la Información y las Comunicaciones de la Universidad de A Coruña (UDC) en este proyecto es el desarrollo de un Sistema de Reconocimiento y Transcripción de Voz (SRTV).
Este sistema de reconocimiento y transcripción de voz tiene como misión fundamental convertir el audio capturado de la voz del médico y convertirlo en texto.
Características
-
La captura de voz se realizará en las consultas médicas usando un micrófono estándar. Para esto se desarrollará una aplicación cliente que se encargará de realizar la captura de audio. Este audio se enviará posteriormente al servicio de transcripción, que se ejecutará en una máquina del Centro de Supercomputación de Galicia (CESGA). Dado el especial entorno en el que se va a ejecutar el sistema, este ha de cumplir los siguientes requisitos funcionales:
- El sistema ha de estar esperando permanentemente por la llegada de ficheros de audio que se envían desde los clientes.
- Una vez recibido el audio éste se almacena:
- Para su posterior envío al servicio de transcripción.
- Para poder almacenar el audio en un repositorio, en caso de ser necesario, para su posterior análisis.
- El audio almacenado se envía al servicio de transcripción.
- Se devuelve la transcripción al cliente.
Además, desde un punto de vista no funcional, este ha de cumplir con estos objetivos:
Concurrencia:
- El sistema ha de ser capaz de gestionar envíos de varios clientes concurrentemente. El servicio determina por configuración el número de peticiones que gestiona concurrentemente.
Escalabilidad:
- De la concurrencia: en caso de ser necesario aumentar el número de envíos gestionados concurrentemente, ha de poder hacerse mediante el aumento de recursos computacionales de la máquina y mediante la configuración de los parámetros de ejecución del servicio.
- Del almacén de datos: en caso de ser necesario el aumento del almacén de archivos recibidos y transcripciones necesarias, ha de poder hacerse simplemente aumentando la capacidad del sistema de almacenamiento del servidor donde se ejecuta el servicio.
Seguridad:
- Protección de la información: el servicio de transcripción estará ubicado en la red del CESGA y sólo aceptará envíos de datos desde equipos de la misma red. Para ello los clientes se conectarán por VPN a la red. Una vez conectados a la misma red podrá enviar datos al servicio; las comunicaciones realizadas con el servicio están cifradas mediante el protocolo de seguridad elegido en el proyecto.
- Autenticación de usuarios o autorización de envío de datos: el servicio creado consiste en un servidor sin estado, por lo que no es necesario ningún servicio de autenticación de usuarios. Tampoco será necesaria la autorización del envío de datos.
Requerimientos de calidad del software
- Disponibilidad: una vez se ejecuta el servicio, este ha de estar disponible 24/7 y ha de aceptar envíos de archivos mientras está disponible. Si el servicio se cayese por fallos del propio servicio, del sistema operativo o de la máquina en la que se ejecuta, será necesario volver a ejecutar el servicio de nueo una vez el error se haya solventado.
- Eficiencia en el manejo de recursos: el servicio ha de consumir los recursos necesarios para satisfacer los requisitos funcionales y no funcionales que se mencionan en esta sección. Todos los recursos temporales que se creen durante su ejecución serán gestionados de manera eficiente y descartados una vez no sean necesarios.
- Flexibilidad para adicionar requerimientos al producto: el software que implementa el servicio ha de ser modular y permitir la adición de nuevos requisitos.
- Instalación: el servicio ha de poder ejecutarse en cualquier máquina en la que se encuentre instalada la máquina virtual de java.
- Portabilidad: el servicio ha de implementarse en Java, permitiendo esto que se instale y ejecute en cualquier sistema para el que haya disponible una versión de la máquina virtual de java.
- Reusabilidad: el software que implementa el servicio ha de ser lo suficientemente modular como para permitir que éste sea reutilizado para incluirlo en otro sistema mayor, bien como componente interno como servicio externo al sistema que lo usa.
Herramientas disponibles
-
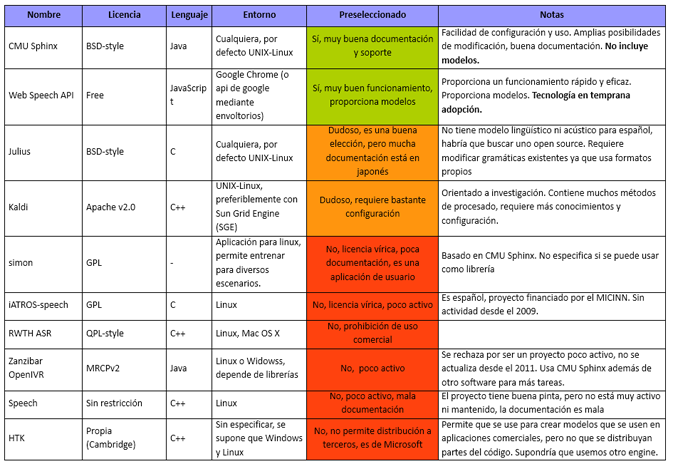
En este punto, se valora si es necesario desarrollar un sistema completamente nuevo, pero parece obvio que la adaptación de uno existente al ámbito de aplicación es una opción mejor, dada la cantidad de software disponible. Se ha realizado, por tanto, un extenso estudio de las principales herramientas del mercado, centrándose en aquellas no comerciales, y fruto de este estudio se ha elaborado la siguiente tabla comparativa con un resumen de las principales características de los sistemas estudiados:
Tras un análisis de las herramientas existentes, incluyendo sistemas como Web Speech API, Julius, Kaldi o HTK y valorando las ventajas e inconvenientes de cada una, se ha optado por utilizar la herramienta CMU Sphinx, que tiene las siguientes ventajas:
- Proyecto activo que se ha usado como base para proyectos conocidos.
- Open source, altamente configurable y adaptable al entorno donde será aplicado.
Arquitectura del sistema
-
La arquitectura global de la aplicación (se representa también el cliente) es la siguiente:
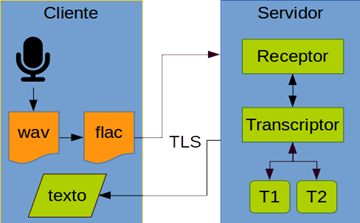
El servicio será proporcionado por un servidor compuesto por un módulo de recepción de datos y un módulo de transcripción. El servidor usará el Receptor para recibir los datos que llegan del cliente, los enviará al Transcriptor y enviará el texto generado de vuelta al cliente.
A continuación se muestra la arquitectura interna de Sphinx (Recognizer), los elementos que éste necesita (y que el servidor ha de proporcionar, son los mostrados en rojo) y cómo el servidor (application) se comunica con él:
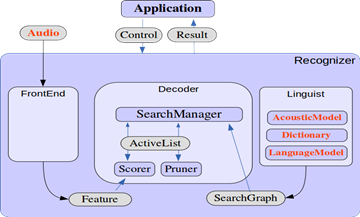
Como se puede ver en la figura, para que el transcriptor funcione correctamente, necesita un modelo acústico, un diccionario y un modelo del lenguaje. De los 3, el que más problemas plantea es la obtención del modelo acústico.
Modelo Acústico
-
Un Modelo Acústico es la representación de un sonido basada en la comprensión del comportamiento del sonido en un lenguaje determinado, es decir, comprende la pronunciación de cada sílaba en un lenguaje determinado, en este caso, en español. Un gran inconveniente de la herramienta seleccionada es que, al igual que la mayoría del resto de herramientas, no dispone de modelo acústico para español.
Por esta razón, es necesario desarrollar uno. Esta tarea es muy costosa, puesto que se estima que son necesarias unas 140 horas de grabación, de distintas voces y textos.
Por tanto, la investigación en esta línea se divide en dos vertientes: desarrollo de un sistema que utilice la herramienta CMU Sphinx, y creación de un modelo acústico que permita que esta herramienta sea utilizable en el reconocimiento de voz.