Principales tareas y objetivos
-
El objetivo del subsistema de procesamiento de registros médicos (SAPRM) es el análisis del informe médico en lenguaje natural no estructurado, en idioma castellano, extrayendo la información en él contenida en una forma estructurada que permita su almacenamiento y explotación. Para ello, combina técnicas de procesado de lenguaje natural que permiten un análisis preliminar del texto y técnicas semánticas para la identificación de conceptos y datos. Para esto último, utiliza la información semántica presente en el sistema (SGM), formada principalmente por terminologías médicas (conceptos relevantes) y arquetipos (modelización del entorno de aplicación).
La implementación se ha realizado usando el framework UIMA, que permite la combinación sencilla de diferentes componentes para analizar información de entrada de tipos variados y obtener la salida deseada. La estructura general de un sistema UIMA es la siguiente:
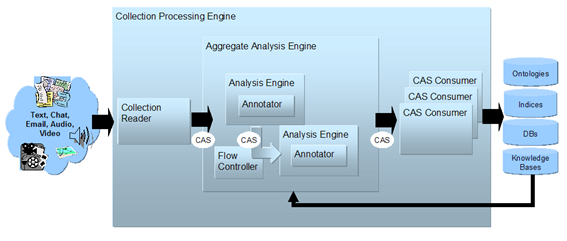
Para el análisis del texto (Analysis Engine), se crea una pipeline de procesos (anotadores), de forma que el texto a analizar va pasando sucesivamente por ellos, y cada uno realiza una tarea de análisis. Se han usado anotadores ya existentes en la plataforma (para identificación de conceptos y patrones) junto con otros de desarrollo propio (para análisis básico de texto e identificación de información médica).